Conservation monitoring schemes are constrained by time and cost and as such study design needs to be optimised to make the most of these available resources. Removal studies are often conducted to protect target species and the aim of such sampling can either be to remove the entire population of an invasive species or to remove a subset of individuals from a source population in order to re-introduce the species to another area, without jeopardising the source population.
Typically the studies are designed in an ad-hoc way with some repeated surveys on a single day, and some with simply daily visits. Sampling of sites is often avoided when weather conditions are considered not favourable. Removed species are trans-located to other habitats considered suitable for the specific species. However, measures to determine whether such translocations, and related re-introduction programmes have been successful are currently lacking. Developing robust approaches for both removal and re-introduction programmes will allow resources to be allocated optimally to ensure monitoring can be carried out for a sufficient period of time, to minimise the risk to the species under study.
This project will develop new statistical approaches to make the most of the information available from removal and reintroduction data. The types of data which can be collected on animal populations are wide-ranging – for example, simple population counts, presence/absence data, presence only data, batch-marked data, and capture-recapture data. The difficulty and survey intensity required to collect these data will also depend on the associated skill set of data collector as well as the resources available to the team or individual responsible for designing the scheme. As well as proposing optimal study design for removal count data, the project will also address how to optimise study design if multiple types of data are collected simultaneously on a population. Further, we will explore how populations could be monitored with multiple types of data collection to better determine how successfully the population has established itself following some form of intervention (such as trans-location of individuals or re-introducing a previously locally extinct species back into an area).
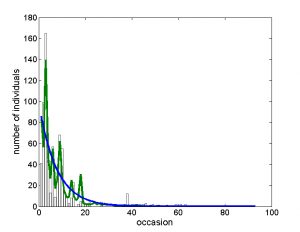
Example of fitting removal models with constant detection (blue line) and time-varying covariate-dependent capture probability (green line) to sample removal data set
When fitting models to data it is possible to consider different structures to the model, for example to account for time-variation within detectability of the species, and therefore a model selection procedure needs to be implemented to select the structure of the model that best represents the observed data. Current approaches require an understanding of the statistical procedures implemented within this model selection step, however the methodological developments proposed within this project are aimed at a user-base who may have no such knowledge. Therefore within the project we will investigate the development of an automated procedure which will both select a best model(s) out of the models considered for the data set and will also assess how well the model(s) fits the observed data. A best candidate model may in fact fit the observed data very poorly and therefore this check of model fit is crucial if the results of the model will be used to make management decisions as otherwise erroneous conclusions could be drawn.